
by Horatiu Dan
Context
It’s been more than 20 years since Spring Framework appeared in the software development landscape and 10 since Spring Boot version 1.0 was released. By now nobody should have any doubt that Spring has created a unique style through which developers are freed from repetitive tasks and left to focus on the business value delivery. As years passed, Spring’s technical depth has continually increased, covering a wide variety of development areas and technologies. On the other hand, its technical breadth has been continually expanded as more focused solutions have been experimented, proof of concepts created and ultimately promoted under the projects’ umbrella (towards the technical depth).
One such example is the new Spring AI project which, according to its reference documentation, aims to ease the development when a generative artificial intelligence layer is aimed to be incorporated into applications. Once again, developers are freed from repetitive tasks and offered with simple interfaces for a direct interaction with the pre-trained models that incorporate the actual processing algorithms.
By interacting with generative pre-trained transformers (GPTs) directly or via Spring AI programmatically, users (developers) do not need to (although it would be useful) posses extensive machine learning knowledge. As an engineer, I strongly believe that even if such (developer) tools can be rather easily and rapidly used to produce results, it is advisable to temper ourselves, to switch to a watchful mode and try to gain a decent understanding of the base concepts first. Moreover, by following this path, the outcome might be even more useful.
Purpose
This article shows how Spring AI can be integrated into a Spring Boot application and fulfill a programmatic interaction with Open AI. It is assumed that prompt design in general (prompt engineering) is a state-of-the-art activity. Consequently, the prompts used during experimentation are quite didactic, without much applicability. The focus here is on the communication interface, that is, Spring AI API.
Before the Implementation
First and foremost, one shall clarify the self rationale for incorporating and utilizing a GPT solution, in addition to the desire to deliver with greater quality, in less time and with lower costs.
Generative AI is said to be good at doing a great deal of time-consuming tasks, quicker, more efficiently and output the results. Moreover, if these results are further validated by experienced and wise humans, the chances to obtain something useful increase. Fortunately, people are still part of the scenery.
Next, one shall resist the temptation to jump right into the implementation and at least dedicate some time to get a bit familiar with the general concepts. An in-depth exploration of generative AI concepts is way beyond the scope of this article. Nevertheless, the “main actors” that appear in the interaction are briefly outlined below.
The Stage – Generative AI is part of Machine Learning that is part of Artificial Intelligence
Input – the provided data (incoming)
Output – the computed results (outgoing)
Large Language Model (LLM) – the fine-tuned algorithm that based on the interpreted input, produces the output
Prompt – a the state-of-the-art interface through which the input is passed to the model
Prompt Template – a component that allows constructing structured parameterized prompts
Tokens – the components the algorithm internally translates the input into, then uses to compile the results and ultimately constructs the output from.
Model’s Context Window – the threshold the model limits the number of tokens count per call (usually, the more tokens are used, the more expensive the operation is)
Finally, an implementation may be started, but as it progresses, it is advisable to revisit and refine the first two steps.
Prompts
In this exercise, we ask for the following:
Write {count = three} reasons why people in {location = Romania} should consider a {job = software architect} job.
These reasons need to be short, so they fit on a poster.
For instance, "{job} jobs are rewarding."
This basically represents the prompt. As advised, a clear topic, a clear meaning of the task and additional helpful pieces of information should be provided as part of the prompts, in order to increase the results’ accuracy.
The prompt contains three parameters, which allow coverage for a wide range of jobs in various locations.
- count – the number of reasons aimed as part of the output
- job – the domain, the job interested in
- location – the country, town, region, etc. the job applicants reside
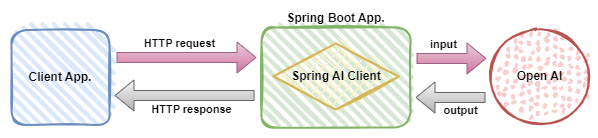
Proof of Concept
In this post, the simple proof of concept aims the following:
- integrate Spring AI in a Spring Boot application and use it
- allow a client to communicate with Open AI via the application
- client issues a parametrized HTTP request to the application
- the application uses a prompt to create the input, sends it to Open AI retrieves the output
- the application sends the response to the client
Set-up
- Java 21
- Maven 3.9.2
- Spring Boot – v. 3.2.2
- Spring AI – v. 0.8.0-SNAPSHOT (still developed, experimental)
Implementation
Spring AI Integration
Normally, this is a basic step not necessarily worth mentioning. Nevertheless, since Spring AI is currently released as a snapshot, in order to be able to integrate the Open AI auto-configuration dependency, one shall add a reference to Spring Milestone / Snapshot repositories.
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
The next step is to add the spring-ai-openai-spring-boot-starter Maven dependency.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>0.8.0-SNAPSHOT</version>
</dependency>
Open AI ChatClient is now part of the application classpath. It is the component used to send the input to Open AI and retrieve the output back.
In order to be able to connect to the AI Model, the spring.ai.openai.api-key property needs to be set-up in the application.properties file.
spring.ai.openai.api-key = api-key-value
Its value represents a valid API Key of the user on behalf which the communication is made. By accessing [Resource 2] one can either sign-up or sign-in and generate one.
Client – Spring Boot Application Communication
The first part of the proof of concept is the communication between a client application (e.g. browser, curl etc.) and the application developed. This is done via a REST controller, accessible via a HTTP GET request.
The URL is /job-reasons together with the three parameters previously outlined when the prompt was defined, which conducts to the following form:
/job-reasons?count={count}&job={job}&location={location}
and the corresponding controller:
@RestController
public class OpenAiController {
@GetMapping("/job-reasons")
public ResponseEntity<String> jobReasons(@RequestParam(value = "count", required = false, defaultValue = "3") int count,
@RequestParam("job") String job,
@RequestParam("location") String location) {
return ResponseEntity.ok().build();
}
}
Since the response from Open AI is going to be a String, the controller returns a ResponseEntity that encapsulates a String. If we run the application and issue a request, currently nothing is returned as part of the response body.
Client – Open AI Communication
Spring AI currently focuses on AI Models that process language and produce language or numbers. Examples of Open AI models in the former category are GPT4-openai or GPT3.5-openai.
For fulfilling an interaction with these AI Models, which actually designate Open AI algorithms, Spring AI provides a uniform interface.
ChatClient interface currently supports text input and output and has a simple contract.
@FunctionalInterface
public interface ChatClient extends ModelClient<Prompt, ChatResponse> {
default String call(String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return call(prompt).getResult().getOutput().getContent();
}
ChatResponse call(Prompt prompt);
}
The actual method of the functional interface is the one usually used.
In the case of our proof of concept, this is exactly what it is needed, a way of calling Open AI and sending the aimed parametrized Prompt as parameter. The following OpenAiService is defined, where an instance of ChatClient is injected.
@Service
public class OpenAiService {
private final ChatClient client;
public OpenAiService(OpenAiChatClient aiClient) {
this.client = aiClient;
}
public String jobReasons(int count, String domain, String location) {
final String promptText = """
Write {count} reasons why people in {location} should consider a {job} job.
These reasons need to be short, so they fit on a poster.
For instance, "{job} jobs are rewarding."
""";
final PromptTemplate promptTemplate = new PromptTemplate(promptText);
promptTemplate.add("count", count);
promptTemplate.add("job", domain);
promptTemplate.add("location", location);
ChatResponse response = client.call(promptTemplate.create());
return response.getResult().getOutput().getContent();
}
}
With the application running, if the following request is performed, from the browser:
http://localhost:8080/gen-ai/job-reasons?count=3&job=software%20architect&location=Romania
the below result is retrieved:
- Lucrative career: Software architect jobs offer competitive salaries and excellent growth opportunities, ensuring financial stability and success in Romania.
- In-demand profession: As the demand for technology continues to grow, software architects are highly sought after in Romania and worldwide, providing abundant job prospects and job security.
- Creative problem-solving: Software architects play a crucial role in designing and developing innovative software solutions, allowing them to unleash their creativity and make a significant impact on various industries.
which is exactly what it was intended – an easy interface through which the Open AI GPT model can be asked to write a couple of reasons about why a certain job in a certain location is appealing.
Adjustments and Observations
The simple proof of concept developed so far mainly uses the default configurations available.
The ChatClient instance may be configured according to the desired needs via various properties. As this is beyond the scope of this writing, only two are exemplified here.
spring.ai.openai.chat.options.model designates the AI Model to use. By default, it is ‘gpt-35-turbo’, but ‘gpt-4’ and ‘gpt-4-32k’ designate the latest versions. Although available, one may not be able to access these using a pay-as-you-go plan, but there are additional pieces of information available on the Open AI website for accommodating it.
Another property worth mentioning is spring.ai.openai.chat.options.temperature. According to the reference documentation, the sampling temperature controls the “creativity of the responses”. It is said that higher values make the output “more random”, while lower ones “more focused and deterministic”. The default value is 0.8, if we decrease it to 0.3, restart the application and ask again with the same request parameters, the below result is retrieved.
- Lucrative career opportunities: Software architect jobs in Romania offer competitive salaries and excellent growth prospects, making it an attractive career choice for individuals seeking financial stability and professional advancement.
- Challenging and intellectually stimulating work: As a software architect, you will be responsible for designing and implementing complex software systems, solving intricate technical problems, and collaborating with talented teams. This role offers continuous learning opportunities and the chance to work on cutting-edge technologies.
- High demand and job security: With the increasing reliance on technology and digital transformation across industries, the demand for skilled software architects is on the rise. Choosing a software architect job in Romania ensures job security and a wide range of employment options, both locally and internationally.
It is visible that the output is way more descriptive in this case.
One last consideration is related to the structure of the output obtained. It would be convenient to have the ability to map the actual payload received to a Java object (class or record, for instance). As of now, the representation is textual and so was the implementation. Output parsers may achieve this, similarly to Spring JDBC’s mapping structures.
In this proof of concept, a BeanOutputParser is used, which allows deserializing the result directly in a Java record as below:
public record JobReasons(String job,
String location,
List<String> reasons) {
}
by taking the {format} as part of the prompt text and providing it as an instruction to the AI Model.
The OpenAiService method becomes:
public JobReasons formattedJobReasons(int count, String job, String location) {
final String promptText = """
Write {count} reasons why people in {location} should consider a {job} job.
These reasons need to be short, so they fit on a poster.
For instance, "{job} jobs are rewarding."
{format}
""";
BeanOutputParser<JobReasons> outputParser = new BeanOutputParser<>(JobReasons.class);
final PromptTemplate promptTemplate = new PromptTemplate(promptText);
promptTemplate.add("count", count);
promptTemplate.add("job", job);
promptTemplate.add("location", location);
promptTemplate.add("format", outputParser.getFormat());
promptTemplate.setOutputParser(outputParser);
final Prompt prompt = promptTemplate.create();
ChatResponse response = client.call(prompt);
return outputParser.parse(response.getResult().getOutput().getContent());
}
When invoking again, the output is as below:
{
"job":"software architect",
"location":"Romania",
"reasons":[
"High demand",
"Competitive salary",
"Opportunities for growth"
]
}
The format is the expected one, but the reasons appear less explanatory, which means additional adjustments are required in order to achieve better usability. From a proof of concept point of view though, this is acceptable, as the focus was on the form.
Conclusions
Prompt design is an important part of the task – the better articulated prompts are, the better the input and the higher the output quality is.
Using Spring AI to integrate with various chat models is quite straightforward – this post showed-cased an Open AI integration.
Nevertheless, in the case of Gen AI in general, just as in the case of almost any technology, it is very important to get familiar at least with the general concepts first. Then, to try to understand the magic behind the way the communication is carried out and only afterwards to start writing “production” code.
Last but not least, it is advisable to further explore the Spring AI API to understand the implementations and remain up-to-date as it evolves and improves.
The code is available here.
References
[1] – Spring AI Reference
[2] – Open AI Platform
[3] – The picture is from San Siro Stadium, taken (NOT AI generated) on the summer of 2023, in Milan, Italy while Coldplay was performing.


